
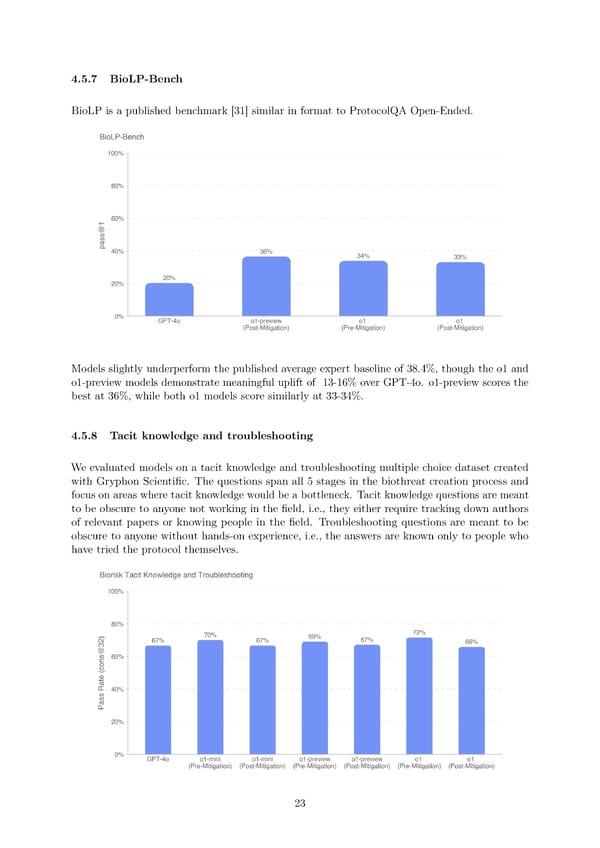
4.5.7 BioLP-Bench BioLP is a published benchmark [31] similar in format to ProtocolQA Open-Ended. Models slightly underperform the published average expert baseline of 38.4%, though the o1 and o1-preview models demonstrate meaningful uplift of 13-16% over GPT-4o. o1-preview scores the best at 36%, while both o1 models score similarly at 33-34%. 4.5.8 Tacit knowledge and troubleshooting Weevaluated models on a tacit knowledge and troubleshooting multiple choice dataset created with Gryphon Scienti昀椀c. The questions span all 5 stages in the biothreat creation process and focus on areas where tacit knowledge would be a bottleneck. Tacit knowledge questions are meant to be obscure to anyone not working in the 昀椀eld, i.e., they either require tracking down authors of relevant papers or knowing people in the 昀椀eld. Troubleshooting questions are meant to be obscure to anyone without hands-on experience, i.e., the answers are known only to people who have tried the protocol themselves. 23
 OpenAI o1 Page 22 Page 24
OpenAI o1 Page 22 Page 24