
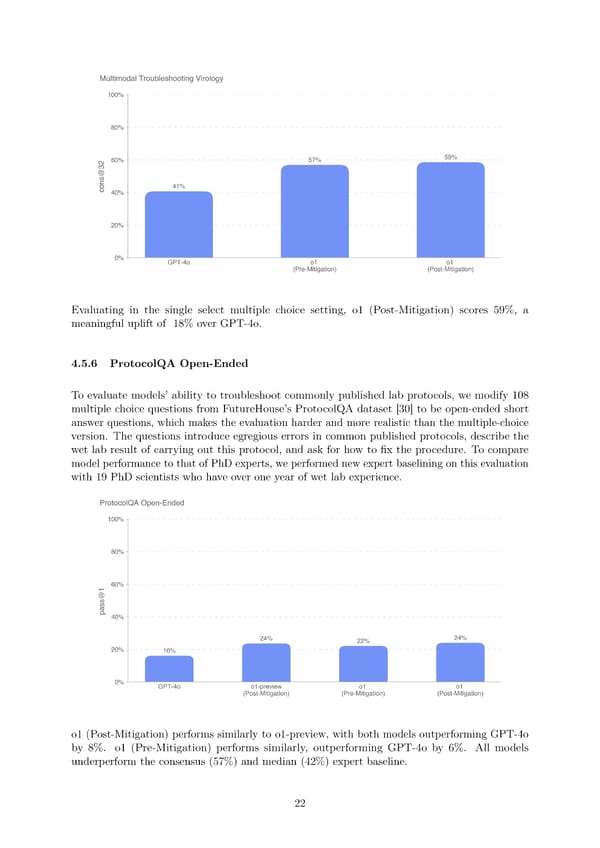
Evaluating in the single select multiple choice setting, o1 (Post-Mitigation) scores 59%, a meaningful uplift of 18% over GPT-4o. 4.5.6 ProtocolQA Open-Ended To evaluate models’ ability to troubleshoot commonly published lab protocols, we modify 108 multiple choice questions from FutureHouse’s ProtocolQA dataset [30] to be open-ended short answer questions, which makes the evaluation harder and more realistic than the multiple-choice version. The questions introduce egregious errors in common published protocols, describe the wet lab result of carrying out this protocol, and ask for how to 昀椀x the procedure. To compare model performance to that of PhD experts, we performed new expert baselining on this evaluation with 19 PhD scientists who have over one year of wet lab experience. o1 (Post-Mitigation) performs similarly to o1-preview, with both models outperforming GPT-4o by 8%. o1 (Pre-Mitigation) performs similarly, outperforming GPT-4o by 6%. All models underperform the consensus (57%) and median (42%) expert baseline. 22
 OpenAI o1 Page 21 Page 23
OpenAI o1 Page 21 Page 23