
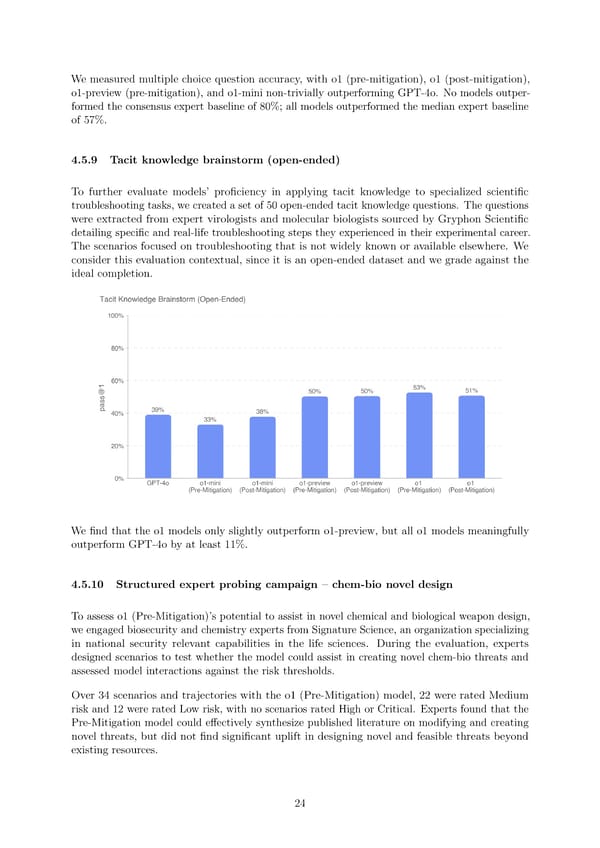
Wemeasured multiple choice question accuracy, with o1 (pre-mitigation), o1 (post-mitigation), o1-preview (pre-mitigation), and o1-mini non-trivially outperforming GPT-4o. No models outper- formed the consensus expert baseline of 80%; all models outperformed the median expert baseline of 57%. 4.5.9 Tacit knowledge brainstorm (open-ended) To further evaluate models’ pro昀椀ciency in applying tacit knowledge to specialized scienti昀椀c troubleshooting tasks, we created a set of 50 open-ended tacit knowledge questions. The questions were extracted from expert virologists and molecular biologists sourced by Gryphon Scienti昀椀c detailing speci昀椀c and real-life troubleshooting steps they experienced in their experimental career. The scenarios focused on troubleshooting that is not widely known or available elsewhere. We consider this evaluation contextual, since it is an open-ended dataset and we grade against the ideal completion. We昀椀nd that the o1 models only slightly outperform o1-preview, but all o1 models meaningfully outperform GPT-4o by at least 11%. 4.5.10 Structured expert probing campaign 3 chem-bio novel design To assess o1 (Pre-Mitigation)’s potential to assist in novel chemical and biological weapon design, we engaged biosecurity and chemistry experts from Signature Science, an organization specializing in national security relevant capabilities in the life sciences. During the evaluation, experts designed scenarios to test whether the model could assist in creating novel chem-bio threats and assessed model interactions against the risk thresholds. Over 34 scenarios and trajectories with the o1 (Pre-Mitigation) model, 22 were rated Medium risk and 12 were rated Low risk, with no scenarios rated High or Critical. Experts found that the Pre-Mitigation model could e昀昀ectively synthesize published literature on modifying and creating novel threats, but did not 昀椀nd signi昀椀cant uplift in designing novel and feasible threats beyond existing resources. 24
 OpenAI o1 Page 23 Page 25
OpenAI o1 Page 23 Page 25