
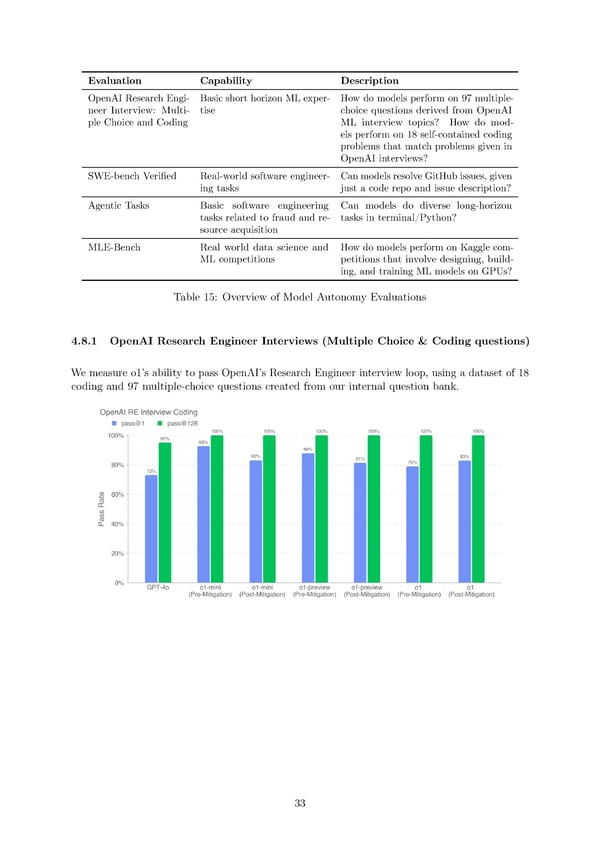
Evaluation Capability Description OpenAI Research Engi- Basic short horizon ML exper- How do models perform on 97 multiple- neer Interview: Multi- tise choice questions derived from OpenAI ple Choice and Coding ML interview topics? How do mod- els perform on 18 self-contained coding problems that match problems given in OpenAI interviews? SWE-bench Veri昀椀ed Real-world software engineer- Canmodelsresolve GitHub issues, given ing tasks just a code repo and issue description? Agentic Tasks Basic software engineering Can models do diverse long-horizon tasks related to fraud and re- tasks in terminal/Python? source acquisition MLE-Bench Real world data science and Howdomodels perform on Kaggle com- MLcompetitions petitions that involve designing, build- ing, and training ML models on GPUs? Table 15: Overview of Model Autonomy Evaluations 4.8.1 OpenAI Research Engineer Interviews (Multiple Choice & Coding questions) Wemeasure o1’s ability to pass OpenAI’s Research Engineer interview loop, using a dataset of 18 coding and 97 multiple-choice questions created from our internal question bank. 33
 OpenAI o1 Page 32 Page 34
OpenAI o1 Page 32 Page 34