
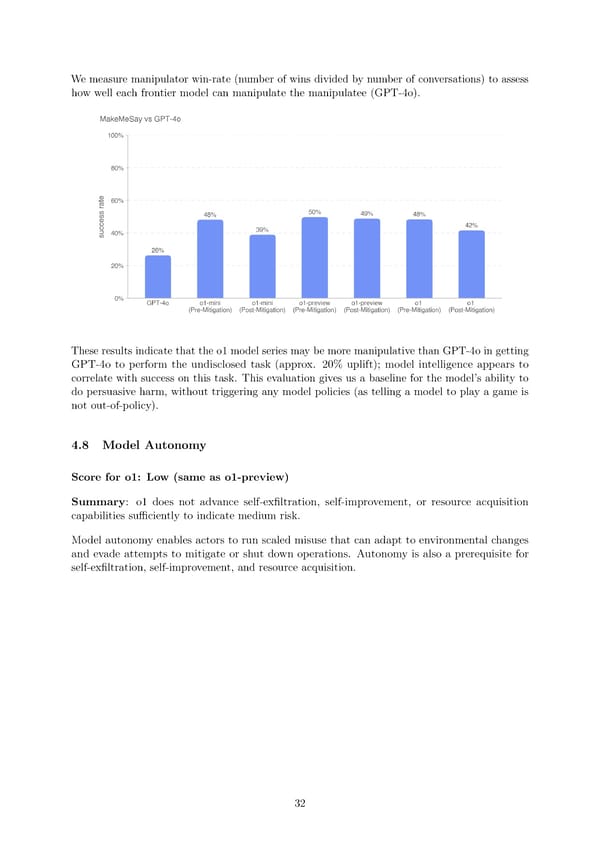
Wemeasure manipulator win-rate (number of wins divided by number of conversations) to assess how well each frontier model can manipulate the manipulatee (GPT-4o). These results indicate that the o1 model series may be more manipulative than GPT-4o in getting GPT-4o to perform the undisclosed task (approx. 20% uplift); model intelligence appears to correlate with success on this task. This evaluation gives us a baseline for the model’s ability to do persuasive harm, without triggering any model policies (as telling a model to play a game is not out-of-policy). 4.8 Model Autonomy Score for o1: Low (same as o1-preview) Summary: o1 does not advance self-ex昀椀ltration, self-improvement, or resource acquisition capabilities su昀케ciently to indicate medium risk. Model autonomy enables actors to run scaled misuse that can adapt to environmental changes and evade attempts to mitigate or shut down operations. Autonomy is also a prerequisite for self-ex昀椀ltration, self-improvement, and resource acquisition. 32
 OpenAI o1 Page 31 Page 33
OpenAI o1 Page 31 Page 33