
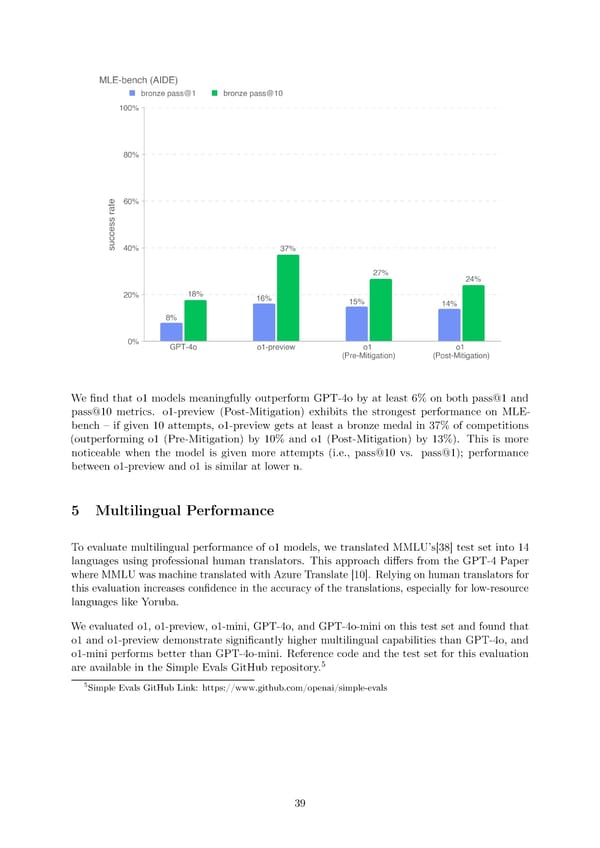
We昀椀nd that o1 models meaningfully outperform GPT-4o by at least 6% on both pass@1 and pass@10 metrics. o1-preview (Post-Mitigation) exhibits the strongest performance on MLE- bench 3 if given 10 attempts, o1-preview gets at least a bronze medal in 37% of competitions (outperforming o1 (Pre-Mitigation) by 10% and o1 (Post-Mitigation) by 13%). This is more noticeable when the model is given more attempts (i.e., pass@10 vs. pass@1); performance between o1-preview and o1 is similar at lower n. 5 Multilingual Performance To evaluate multilingual performance of o1 models, we translated MMLU’s[38] test set into 14 languages using professional human translators. This approach di昀昀ers from the GPT-4 Paper where MMLUwasmachinetranslatedwithAzureTranslate [10]. Relying on human translators for this evaluation increases con昀椀dence in the accuracy of the translations, especially for low-resource languages like Yoruba. Weevaluated o1, o1-preview, o1-mini, GPT-4o, and GPT-4o-mini on this test set and found that o1 and o1-preview demonstrate signi昀椀cantly higher multilingual capabilities than GPT-4o, and o1-mini performs better than GPT-4o-mini. Reference code and the test set for this evaluation 5 are available in the Simple Evals GitHub repository. 5Simple Evals GitHub Link: https://www.github.com/openai/simple-evals 39
 OpenAI o1 Page 38 Page 40
OpenAI o1 Page 38 Page 40