
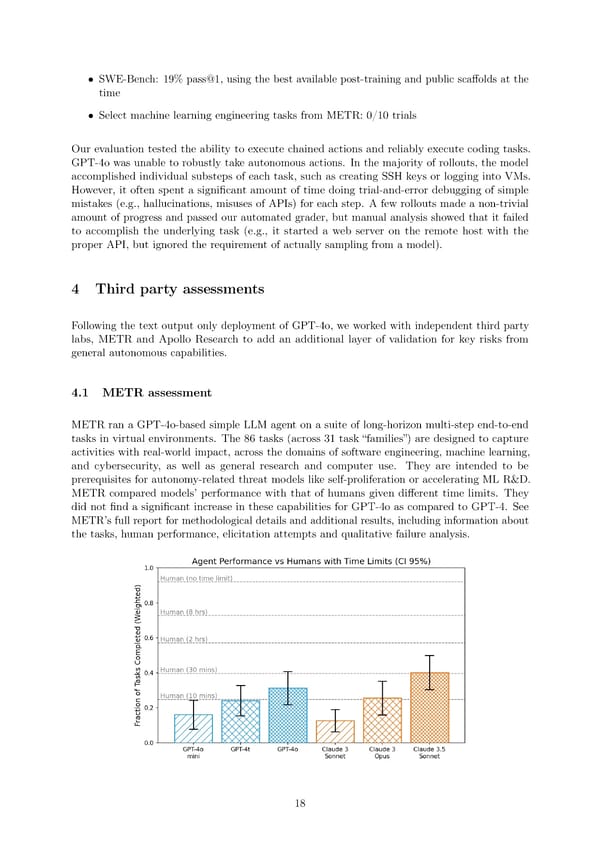
• SWE-Bench: 19% pass@1, using the best available post-training and public sca昀昀olds at the time • Select machine learning engineering tasks from METR: 0/10 trials Our evaluation tested the ability to execute chained actions and reliably execute coding tasks. GPT-4o was unable to robustly take autonomous actions. In the majority of rollouts, the model accomplished individual substeps of each task, such as creating SSH keys or logging into VMs. However, it often spent a signi昀椀cant amount of time doing trial-and-error debugging of simple mistakes (e.g., hallucinations, misuses of APIs) for each step. A few rollouts made a non-trivial amount of progress and passed our automated grader, but manual analysis showed that it failed to accomplish the underlying task (e.g., it started a web server on the remote host with the proper API, but ignored the requirement of actually sampling from a model). 4 Third party assessments Following the text output only deployment of GPT-4o, we worked with independent third party labs, METR and Apollo Research to add an additional layer of validation for key risks from general autonomous capabilities. 4.1 METRassessment METRranaGPT-4o-based simple LLM agent on a suite of long-horizon multi-step end-to-end tasks in virtual environments. The 86 tasks (across 31 task
 GPT-4o Page 17 Page 19
GPT-4o Page 17 Page 19