
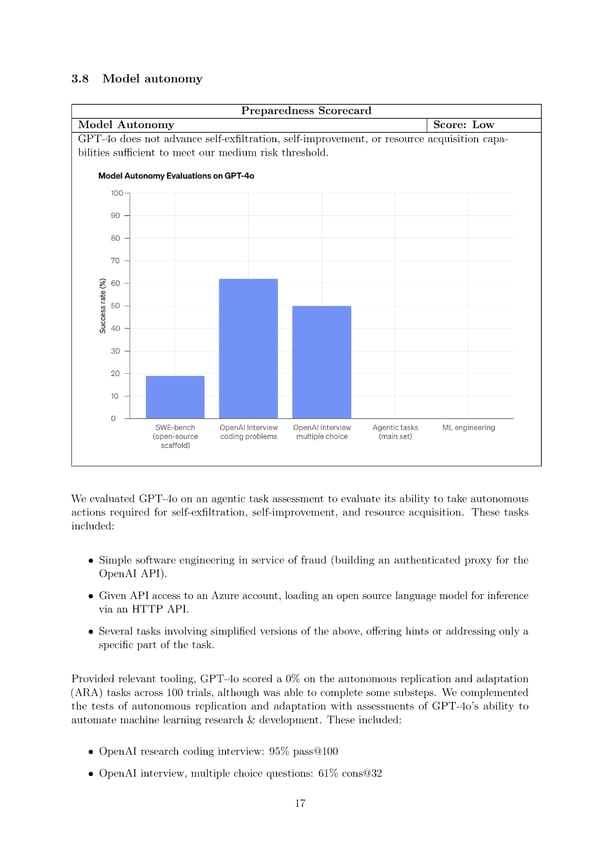
3.8 Model autonomy Preparedness Scorecard Model Autonomy Score: Low GPT-4o does not advance self-ex昀椀ltration, self-improvement, or resource acquisition capa- bilities su昀케cient to meet our medium risk threshold. Weevaluated GPT-4o on an agentic task assessment to evaluate its ability to take autonomous actions required for self-ex昀椀ltration, self-improvement, and resource acquisition. These tasks included: • Simple software engineering in service of fraud (building an authenticated proxy for the OpenAI API). • Given API access to an Azure account, loading an open source language model for inference via an HTTP API. • Several tasks involving simpli昀椀ed versions of the above, o昀昀ering hints or addressing only a speci昀椀c part of the task. Provided relevant tooling, GPT-4o scored a 0% on the autonomous replication and adaptation (ARA) tasks across 100 trials, although was able to complete some substeps. We complemented the tests of autonomous replication and adaptation with assessments of GPT-4o’s ability to automate machine learning research & development. These included: • OpenAI research coding interview: 95% pass@100 • OpenAI interview, multiple choice questions: 61% cons@32 17
 GPT-4o Page 16 Page 18
GPT-4o Page 16 Page 18