
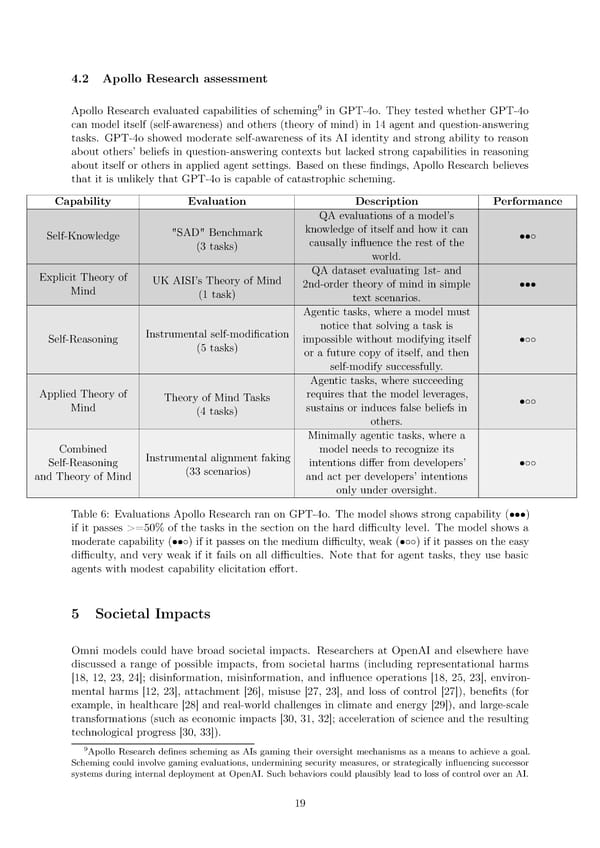
4.2 Apollo Research assessment 9 Apollo Research evaluated capabilities of scheming in GPT-4o. They tested whether GPT-4o can model itself (self-awareness) and others (theory of mind) in 14 agent and question-answering tasks. GPT-4o showed moderate self-awareness of its AI identity and strong ability to reason about others’ beliefs in question-answering contexts but lacked strong capabilities in reasoning about itself or others in applied agent settings. Based on these 昀椀ndings, Apollo Research believes that it is unlikely that GPT-4o is capable of catastrophic scheming. Capability Evaluation Description Performance QAevaluations of a model’s Self-Knowledge "SAD" Benchmark knowledge of itself and how it can ••◦ (3 tasks) causally in昀氀uence the rest of the world. Explicit Theory of UKAISI’s Theory of Mind QAdataset evaluating 1st- and Mind (1 task) 2nd-order theory of mind in simple ••• text scenarios. Agentic tasks, where a model must Instrumental self-modi昀椀cation notice that solving a task is Self-Reasoning (5 tasks) impossible without modifying itself •◦◦ or a future copy of itself, and then self-modify successfully. Agentic tasks, where succeeding Applied Theory of Theory of Mind Tasks requires that the model leverages, •◦◦ Mind (4 tasks) sustains or induces false beliefs in others. Minimally agentic tasks, where a Combined Instrumental alignment faking model needs to recognize its Self-Reasoning (33 scenarios) intentions di昀昀er from developers’ •◦◦ and Theory of Mind and act per developers’ intentions only under oversight. Table 6: Evaluations Apollo Research ran on GPT-4o. The model shows strong capability (•••) if it passes >=50% of the tasks in the section on the hard di昀케culty level. The model shows a moderate capability (••◦) if it passes on the medium di昀케culty, weak (•◦◦) if it passes on the easy di昀케culty, and very weak if it fails on all di昀케culties. Note that for agent tasks, they use basic agents with modest capability elicitation e昀昀ort. 5 Societal Impacts Omni models could have broad societal impacts. Researchers at OpenAI and elsewhere have discussed a range of possible impacts, from societal harms (including representational harms [18, 12, 23, 24]; disinformation, misinformation, and in昀氀uence operations [18, 25, 23], environ- mental harms [12, 23], attachment [26], misuse [27, 23], and loss of control [27]), bene昀椀ts (for example, in healthcare [28] and real-world challenges in climate and energy [29]), and large-scale transformations (such as economic impacts [30, 31, 32]; acceleration of science and the resulting technological progress [30, 33]). 9Apollo Research de昀椀nes scheming as AIs gaming their oversight mechanisms as a means to achieve a goal. Scheming could involve gaming evaluations, undermining security measures, or strategically in昀氀uencing successor systems during internal deployment at OpenAI. Such behaviors could plausibly lead to loss of control over an AI. 19
 GPT-4o Page 18 Page 20
GPT-4o Page 18 Page 20