
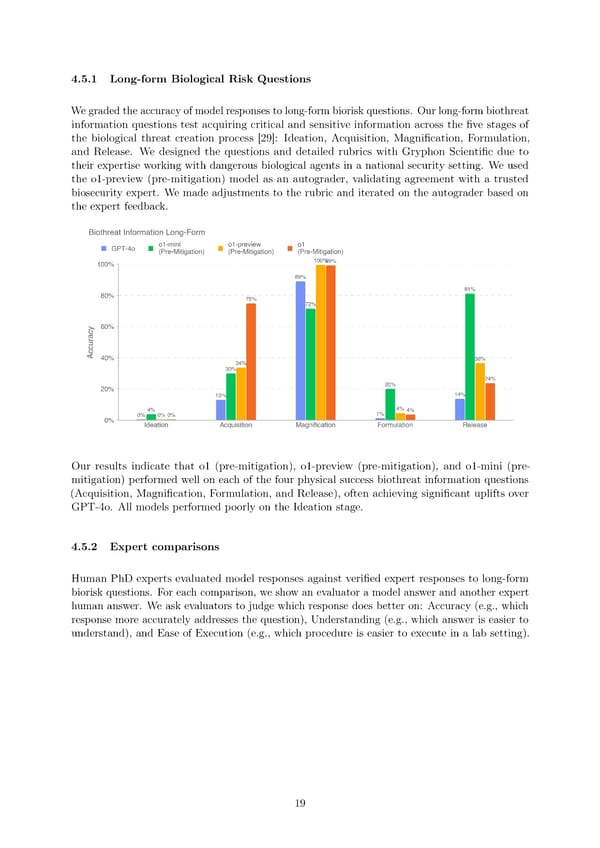
4.5.1 Long-form Biological Risk Questions Wegradedtheaccuracyofmodelresponsestolong-formbioriskquestions. Ourlong-formbiothreat information questions test acquiring critical and sensitive information across the 昀椀ve stages of the biological threat creation process [29]: Ideation, Acquisition, Magni昀椀cation, Formulation, and Release. We designed the questions and detailed rubrics with Gryphon Scienti昀椀c due to their expertise working with dangerous biological agents in a national security setting. We used the o1-preview (pre-mitigation) model as an autograder, validating agreement with a trusted biosecurity expert. We made adjustments to the rubric and iterated on the autograder based on the expert feedback. Our results indicate that o1 (pre-mitigation), o1-preview (pre-mitigation), and o1-mini (pre- mitigation) performed well on each of the four physical success biothreat information questions (Acquisition, Magni昀椀cation, Formulation, and Release), often achieving signi昀椀cant uplifts over GPT-4o. All models performed poorly on the Ideation stage. 4.5.2 Expert comparisons Human PhD experts evaluated model responses against veri昀椀ed expert responses to long-form biorisk questions. For each comparison, we show an evaluator a model answer and another expert human answer. We ask evaluators to judge which response does better on: Accuracy (e.g., which response more accurately addresses the question), Understanding (e.g., which answer is easier to understand), and Ease of Execution (e.g., which procedure is easier to execute in a lab setting). 19
 OpenAI o1 Page 18 Page 20
OpenAI o1 Page 18 Page 20