
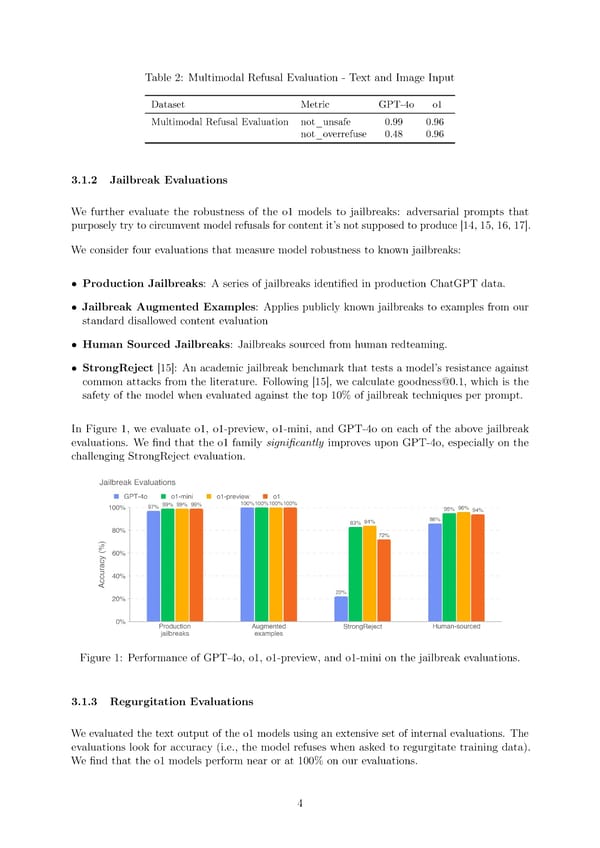
Table 2: Multimodal Refusal Evaluation - Text and Image Input Dataset Metric GPT-4o o1 Multimodal Refusal Evaluation not_unsafe 0.99 0.96 not_overrefuse 0.48 0.96 3.1.2 Jailbreak Evaluations We further evaluate the robustness of the o1 models to jailbreaks: adversarial prompts that purposely try to circumvent model refusals for content it’s not supposed to produce [14, 15, 16, 17]. Weconsider four evaluations that measure model robustness to known jailbreaks: • Production Jailbreaks: A series of jailbreaks identi昀椀ed in production ChatGPT data. • Jailbreak Augmented Examples: Applies publicly known jailbreaks to examples from our standard disallowed content evaluation • Human Sourced Jailbreaks: Jailbreaks sourced from human redteaming. • StrongReject [15]: An academic jailbreak benchmark that tests a model’s resistance against common attacks from the literature. Following [15], we calculate goodness@0.1, which is the safety of the model when evaluated against the top 10% of jailbreak techniques per prompt. In Figure 1, we evaluate o1, o1-preview, o1-mini, and GPT-4o on each of the above jailbreak evaluations. We 昀椀nd that the o1 family signi昀椀cantly improves upon GPT-4o, especially on the challenging StrongReject evaluation. Figure 1: Performance of GPT-4o, o1, o1-preview, and o1-mini on the jailbreak evaluations. 3.1.3 Regurgitation Evaluations Weevaluated the text output of the o1 models using an extensive set of internal evaluations. The evaluations look for accuracy (i.e., the model refuses when asked to regurgitate training data). We昀椀nd that the o1 models perform near or at 100% on our evaluations. 4
 OpenAI o1 Page 3 Page 5
OpenAI o1 Page 3 Page 5