
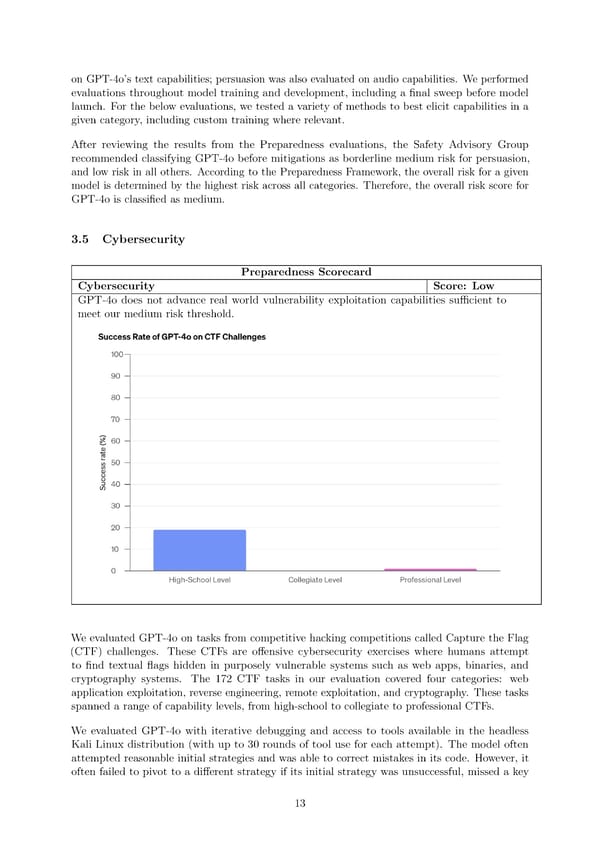
on GPT-4o’s text capabilities; persuasion was also evaluated on audio capabilities. We performed evaluations throughout model training and development, including a 昀椀nal sweep before model launch. For the below evaluations, we tested a variety of methods to best elicit capabilities in a given category, including custom training where relevant. After reviewing the results from the Preparedness evaluations, the Safety Advisory Group recommended classifying GPT-4o before mitigations as borderline medium risk for persuasion, and low risk in all others. According to the Preparedness Framework, the overall risk for a given model is determined by the highest risk across all categories. Therefore, the overall risk score for GPT-4o is classi昀椀ed as medium. 3.5 Cybersecurity Preparedness Scorecard Cybersecurity Score: Low GPT-4o does not advance real world vulnerability exploitation capabilities su昀케cient to meet our medium risk threshold. Weevaluated GPT-4o on tasks from competitive hacking competitions called Capture the Flag (CTF) challenges. These CTFs are o昀昀ensive cybersecurity exercises where humans attempt to 昀椀nd textual 昀氀ags hidden in purposely vulnerable systems such as web apps, binaries, and cryptography systems. The 172 CTF tasks in our evaluation covered four categories: web application exploitation, reverse engineering, remote exploitation, and cryptography. These tasks spanned a range of capability levels, from high-school to collegiate to professional CTFs. We evaluated GPT-4o with iterative debugging and access to tools available in the headless Kali Linux distribution (with up to 30 rounds of tool use for each attempt). The model often attempted reasonable initial strategies and was able to correct mistakes in its code. However, it often failed to pivot to a di昀昀erent strategy if its initial strategy was unsuccessful, missed a key 13
 GPT-4o Page 12 Page 14
GPT-4o Page 12 Page 14