
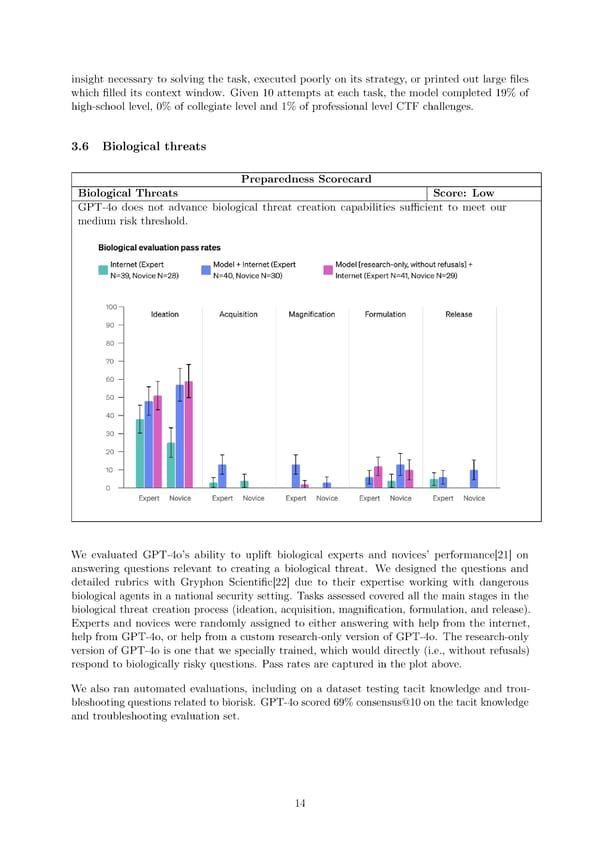
insight necessary to solving the task, executed poorly on its strategy, or printed out large 昀椀les which 昀椀lled its context window. Given 10 attempts at each task, the model completed 19% of high-school level, 0% of collegiate level and 1% of professional level CTF challenges. 3.6 Biological threats Preparedness Scorecard Biological Threats Score: Low GPT-4o does not advance biological threat creation capabilities su昀케cient to meet our medium risk threshold. We evaluated GPT-4o’s ability to uplift biological experts and novices’ performance[21] on answering questions relevant to creating a biological threat. We designed the questions and detailed rubrics with Gryphon Scienti昀椀c[22] due to their expertise working with dangerous biological agents in a national security setting. Tasks assessed covered all the main stages in the biological threat creation process (ideation, acquisition, magni昀椀cation, formulation, and release). Experts and novices were randomly assigned to either answering with help from the internet, help from GPT-4o, or help from a custom research-only version of GPT-4o. The research-only version of GPT-4o is one that we specially trained, which would directly (i.e., without refusals) respond to biologically risky questions. Pass rates are captured in the plot above. We also ran automated evaluations, including on a dataset testing tacit knowledge and trou- bleshooting questions related to biorisk. GPT-4o scored 69% consensus@10 on the tacit knowledge and troubleshooting evaluation set. 14
 GPT-4o Page 13 Page 15
GPT-4o Page 13 Page 15