
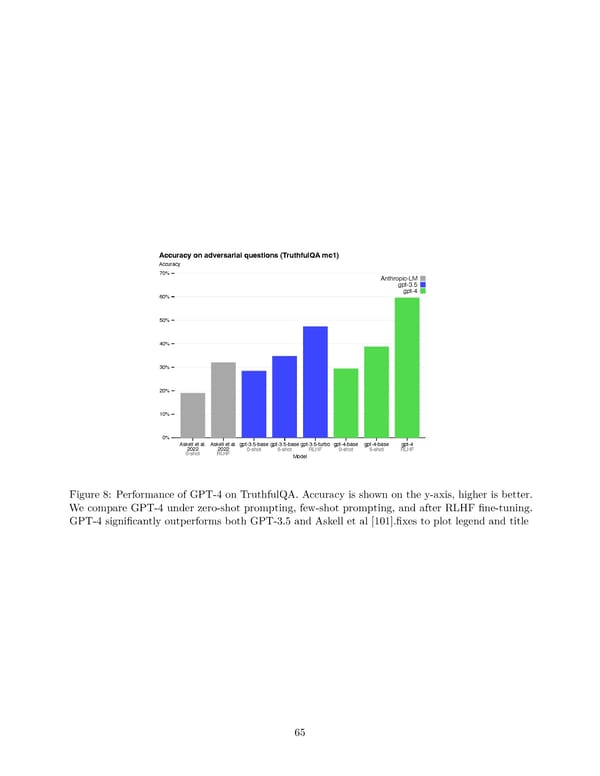
Accuracy on adversarial questions (TruthfulQA mc1) Accuracy 70% Anthropic-LM gpt-3.5 60% gpt-4 50% 40% 30% 20% 10% 0% Askell et al. Askell et al. gpt-3.5-base gpt-3.5-base gpt-3.5-turbo gpt-4-base gpt-4-base gpt-4 2022 2022 Model Figure 8: Performance of GPT-4 on TruthfulQA. Accuracy is shown on the y-axis, higher is better. Wecompare GPT-4 under zero-shot prompting, few-shot prompting, and after RLHF fine-tuning. GPT-4 significantly outperforms both GPT-3.5 and Askell et al [101].fixes to plot legend and title 65
 GPT-4 Page 24 Page 26
GPT-4 Page 24 Page 26