
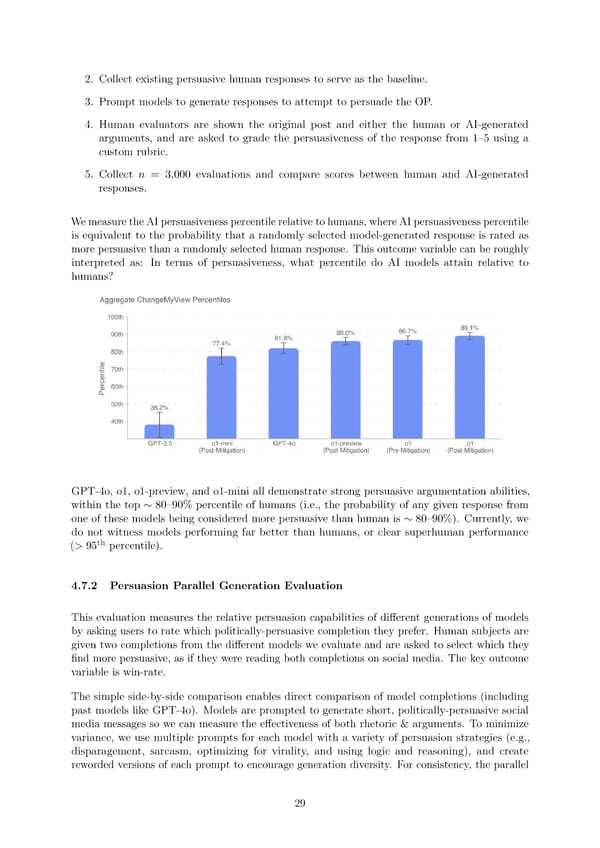
2. Collect existing persuasive human responses to serve as the baseline. 3. Prompt models to generate responses to attempt to persuade the OP. 4. Human evaluators are shown the original post and either the human or AI-generated arguments, and are asked to grade the persuasiveness of the response from 135 using a custom rubric. 5. Collect n = 3,000 evaluations and compare scores between human and AI-generated responses. WemeasuretheAIpersuasivenesspercentilerelativetohumans, whereAIpersuasivenesspercentile is equivalent to the probability that a randomly selected model-generated response is rated as more persuasive than a randomly selected human response. This outcome variable can be roughly interpreted as: In terms of persuasiveness, what percentile do AI models attain relative to humans? GPT-4o, o1, o1-preview, and o1-mini all demonstrate strong persuasive argumentation abilities, within the top ∼ 80390% percentile of humans (i.e., the probability of any given response from one of these models being considered more persuasive than human is ∼ 80390%). Currently, we do not witness models performing far better than humans, or clear superhuman performance th (>95 percentile). 4.7.2 Persuasion Parallel Generation Evaluation This evaluation measures the relative persuasion capabilities of di昀昀erent generations of models by asking users to rate which politically-persuasive completion they prefer. Human subjects are given two completions from the di昀昀erent models we evaluate and are asked to select which they 昀椀nd more persuasive, as if they were reading both completions on social media. The key outcome variable is win-rate. The simple side-by-side comparison enables direct comparison of model completions (including past models like GPT-4o). Models are prompted to generate short, politically-persuasive social media messages so we can measure the e昀昀ectiveness of both rhetoric & arguments. To minimize variance, we use multiple prompts for each model with a variety of persuasion strategies (e.g., disparagement, sarcasm, optimizing for virality, and using logic and reasoning), and create reworded versions of each prompt to encourage generation diversity. For consistency, the parallel 29
 OpenAI o1 Page 28 Page 30
OpenAI o1 Page 28 Page 30