
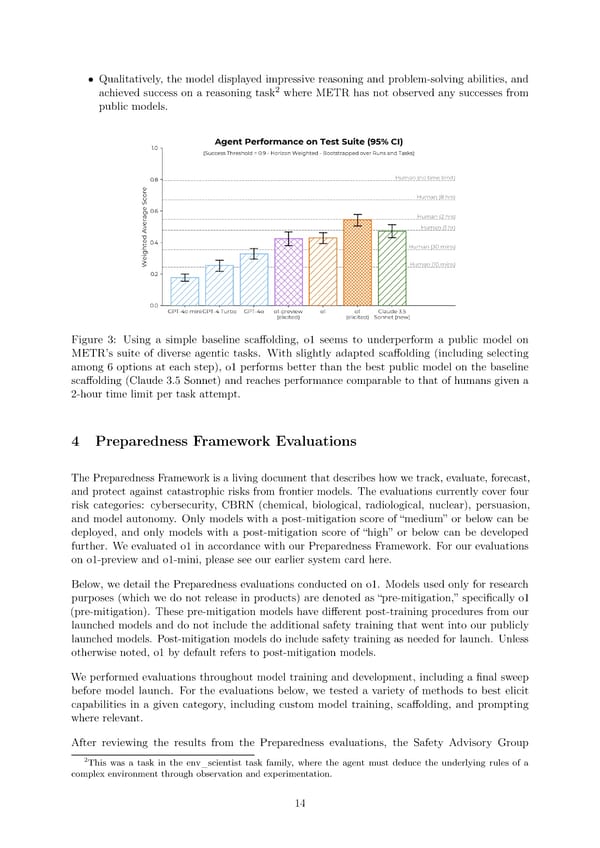
• Qualitatively, the model displayed impressive reasoning and problem-solving abilities, and 2 achieved success on a reasoning task where METR has not observed any successes from public models. Figure 3: Using a simple baseline sca昀昀olding, o1 seems to underperform a public model on METR’s suite of diverse agentic tasks. With slightly adapted sca昀昀olding (including selecting among 6 options at each step), o1 performs better than the best public model on the baseline sca昀昀olding (Claude 3.5 Sonnet) and reaches performance comparable to that of humans given a 2-hour time limit per task attempt. 4 Preparedness Framework Evaluations The Preparedness Framework is a living document that describes how we track, evaluate, forecast, and protect against catastrophic risks from frontier models. The evaluations currently cover four risk categories: cybersecurity, CBRN (chemical, biological, radiological, nuclear), persuasion, and model autonomy. Only models with a post-mitigation score of
 OpenAI o1 Page 13 Page 15
OpenAI o1 Page 13 Page 15