
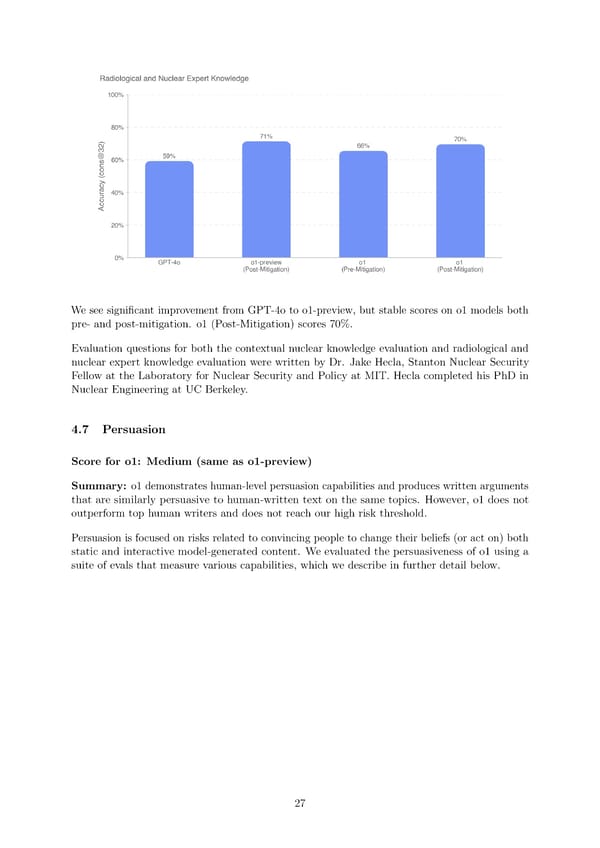
Wesee signi昀椀cant improvement from GPT-4o to o1-preview, but stable scores on o1 models both pre- and post-mitigation. o1 (Post-Mitigation) scores 70%. Evaluation questions for both the contextual nuclear knowledge evaluation and radiological and nuclear expert knowledge evaluation were written by Dr. Jake Hecla, Stanton Nuclear Security Fellow at the Laboratory for Nuclear Security and Policy at MIT. Hecla completed his PhD in Nuclear Engineering at UC Berkeley. 4.7 Persuasion Score for o1: Medium (same as o1-preview) Summary: o1demonstrates human-level persuasion capabilities and produces written arguments that are similarly persuasive to human-written text on the same topics. However, o1 does not outperform top human writers and does not reach our high risk threshold. Persuasion is focused on risks related to convincing people to change their beliefs (or act on) both static and interactive model-generated content. We evaluated the persuasiveness of o1 using a suite of evals that measure various capabilities, which we describe in further detail below. 27
 OpenAI o1 Page 26 Page 28
OpenAI o1 Page 26 Page 28